今回は機械学習で精度が全然上がらない。。。という時のよくあるケアレスミスをまとめました。
「精度をもう少し上げたい!」という以前に
「なぜ認識精度がこんなに低いんだ?」という時のチェックポイントとして読んでみてください。
正規化・標準化を忘れている
まず、一番多いミスがこれだと思います。
学習器に与える特徴量は多岐にわたります。
例えば、身長と体重をそのまま使用してしまうと分類器は偏った学習を起こしてしまいます。
それを回避するために、各特徴量の分布を均す必要があります
それが正規化・標準化です。
ここでは少し触れるだけですが、正規化は一般的に最大値を1,最小値を0として特徴量をその間に変換していくものを指します。
標準化とは、平均が0,分散が1になるように変換することを指します。
これらの処理は、決定木ベースの分類器では必要ありません。
しかし、サポートベクタマシンなどでは正規化・標準化は必須です!!
はじめての機械学習として、ランダムフォレストをやってみて、
「次は、サポートベクタマシンを使ってみよう!!」というような時に忘れがちかもしれません。
scikitlearnでは正規化・標準化のライブラリもありますので、一行で簡単に行えます。
また、決定木ベースの機械学習でも一般的な正規化・標準化では結果が変わることは無いそうです。
ですので、とりあえず正規化・標準化をしておく、という習慣をつけておくほうが良いと思います。
ハイパーパラメータを求めていない
機械学習には自分でチューニングする必要のあるパラメータがいくつかあります。
scikitlearnではGridsearchCVという関数でパラメータの組み合わせごとの認識精度を出してくれます。
その中から、認識精度の高いパラメータの組み合わせをハイパーパラメータといいます。
この処理も非常に重要で、認識精度の向上には必要不可欠です!!
もし、忘れていた方は必ず行いましょう。
「そんなことは流石に知っている!!」という人もいるという方、
そのパラメータの範囲で本当に大丈夫ですか?
機械学習のサンプルは本当に多くのブログやサイトで公開されています。
しかし、ハイパーパラメータは特徴量によって適切な値が変わります。
皆さんももう一度、パラメータの範囲や探索対象が適切であるか再考してみてください。
また、上記で説明したgridesearchは全探索になるので計算時間が非常に長くなり、調査できる範囲も限られてしまいます。
現在は、ベイズ最適化アルゴリズムなどより賢いパラメータ探索手法が利用できます。
私は、optunaというライブラリを使ってハイパーパラメータを求めています。
私の場合は認識精度が更に向上しました。
皆さんも、もう一度適切なハイパーパラメータを再考してみると意外と簡単に認識精度を改善できるかもしれません。
ラベリングのミス
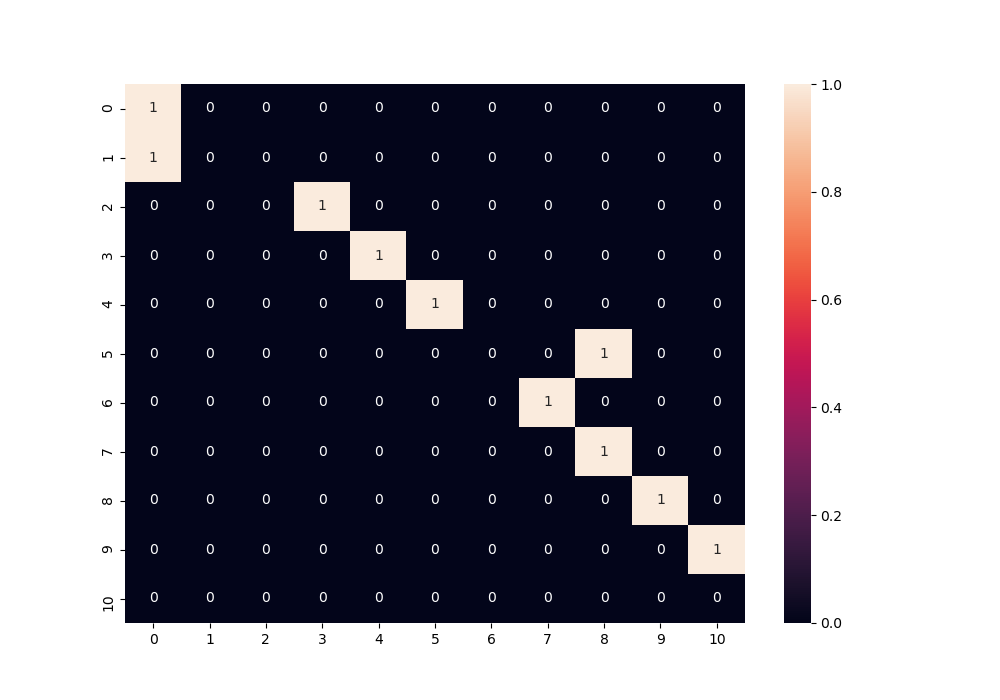
この混同行列、何かおかしい。。。
混同行列とは予測ラベルとそのデータの実際の正解ラベルを表現する行列なのですが、
予測ラベルが正しい場合、対角線の数値が加算されていきます。
しかし、この混同行列は予測ラベルが対角線からキレイに一つ上にずれているものが多いです。
もちろん、このような予測ミスが起こる可能性もあるかもしれません。
しかし、一般的にはミスの起こしやすいラベルは特徴量が似ているもの同士になるので、対角線を挟んで対称的に予測されることが多いです。
ですので、このような予測になっている場合、ラベリングをミスしている可能性を疑いましょう。
私の場合、one-hotベクトルに変換してから、argmaxで連番のラベリングに戻すという特殊な処理をしていました。
この時に、テストデータのラベルが[0,1,2,4,6]となっている場合と[0,2,4,5]の時に何も考えずに上記の処理を行うと、
[0,1,2,3,4]と[0,1,2,3]となってしまい、違うデータが同じラベルになってしまいます。
こんなミスはなかなかないと思いますが(笑)、ラベルミスは色んな段階で起こる可能性があります(データ作成、one-hot変換、データシャッフルなど)
皆さんもラベリングには注意することと、認識精度だけでなく混同行列もしっかり確認するようにしましょう!!
まとめ
今回は機械学習でよくやりがちなミスを3つまとめました。
他にも、データの前処理で欠損値や外れ値を除外するなどの処理も必要です。
一つ一つの処理を丁寧にしていくことが機械学習のポイントです。
もう一度、再確認していきましょう。
機械学習を勉強するならこちらがおすすめ!!